DEX文件结构与解析
Dex是Dalvik虚拟机的执行文件,对于每一个开发者来说,他的结构对于开发这至关重要,也是我们优化的一个方面,虽然很多工作是Android Stuido和其对应的工具进行的,但是我们需要知道他的基础结构和工作原理.由于近期的工作原因,特意研究了一下dex的完整结构,并且用kotlin写了完整的结构解析代码,除了dex具体的代码解析以外的其他结构解析都已经完成.特此总结一下学到的东西,希望与大家一起进步.
前期准备工作
1.我们在探索Dex文件结构时候需要使用一些工具,我个人推荐使用010Editor,加上Dex模板,这样更好的方便我们分析Dex的结构
2.分析的Dex文件是我自己用Timber(一个开元音乐播放器)代码编译的。如果需要可以自己找个合适的分析对象
正式开始
将dex从apk中解压出来,拖入010editor中,此时因为dex文件比较大,010Editor会提示是否继续进行分析
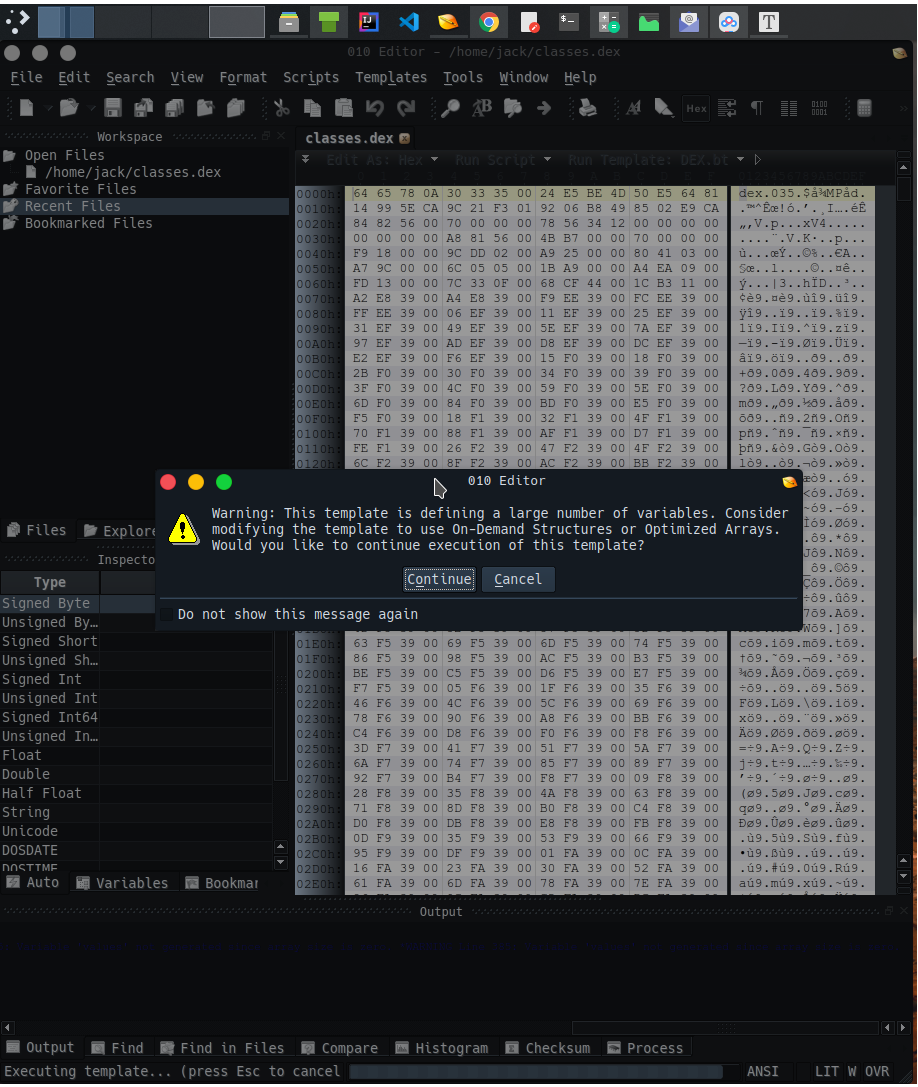
分析完成以后会在下面产生一个结构列表,我们分析就靠这个结构列表和对应的数据了。

Dex头部
首先我们用鼠标选中结构的第一行,可以看到上面文本去默认会被高亮,这第一段里面的就是Dex文件的头部
MagicNumber
Dex文件头的前8个byte是用来识别dex文件的MagicNumber,内容是Dex.035,并以00结尾,十六进制值为 64 65 78 0A 30 33 35 00
CheckSum
Dex文件的adler32校验和,长度4个字节,校验文件除去 maigc、checksum 外余下的所有文件区域
SHA1 Signature
接下来的20个字节是SHA1的签名
File Size 文件长度
文件长度4个字节,所以单个Dex文件大小不可能超过4GB,但是因为可以拆分分多个Dex,所以使用4字节也是足够了
Header Size
长度4字节,标记整个头部的长度,这里的值是0x00 00 00 70,十进制是112,如果我们选中010Editor下面的结构框的第一个名字叫 struct header_item dex_header 的item ,我们就能发现,上面选中的结构大小刚好是0H到6FH,共计70H个数据,这个值一般是固定的
EndianTag
长度4个字节,用来标记大小端,默认值是0x12 34 56 78,指定cpu的运行环境是大端还是小端,默认的intel使用的是小端,所以在010Editor上面看到的是78 56 34 12,这个请注意!!!
LinkSize & LinkOff 字段
这两个字段指定连接段的大小和对应的文件偏移地址,通常情况都为0,linksize为0表示静态链接
mapOff
指定了DexMapList的结构在Dex文件中的位置偏移,这个DexMapList结构是其他结构的一个数据大纲,里面记录了这些结构的一些信息。
struct DexMapList {
u4 size; /* DexMapItem的个数 */
DexMapItem list[1]; /* DexMapItem的结构 */
};
struct DexMapItem {
u2 type; /* kDexType开头的类型 */
u2 unused; /* 未使用,用于字节对齐 */
u4 size; /* type指定类型的个数,它们在dex文件中连续存放 */
u4 offset; /* 指定类型数据的文件偏移 */
};
/* type字段为一个枚举常量,通过类型名称很容易判断它的具体类型。 */
/* map item type codes */
enum {
kDexTypeHeaderItem = 0x0000,
kDexTypeStringIdItem = 0x0001,
kDexTypeTypeIdItem = 0x0002,
kDexTypeProtoIdItem = 0x0003,
kDexTypeFieldIdItem = 0x0004,
kDexTypeMethodIdItem = 0x0005,
kDexTypeClassDefItem = 0x0006,
kDexTypeMapList = 0x1000,
kDexTypeTypeList = 0x1001,
kDexTypeAnnotationSetRefList = 0x1002,
kDexTypeAnnotationSetItem = 0x1003,
kDexTypeClassDataItem = 0x2000,
kDexTypeCodeItem = 0x2001,
kDexTypeStringDataItem = 0x2002,
kDexTypeDebugInfoItem = 0x2003,
kDexTypeAnnotationItem = 0x2004,
kDexTypeEncodedArrayItem = 0x2005,
kDexTypeAnnotationsDirectoryItem = 0x2006,
};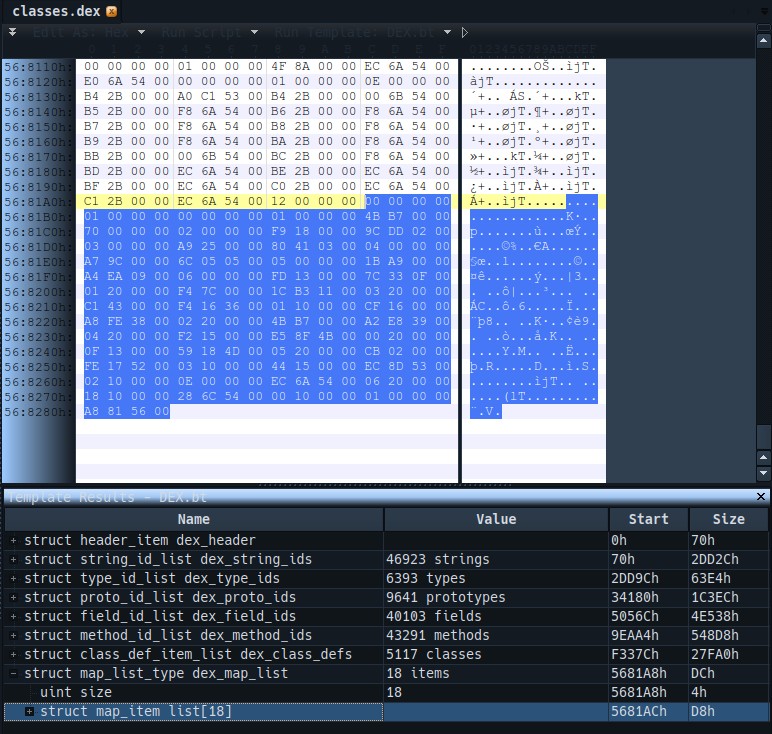
这个dex_map_list 结构保存在DEX文件的最末尾处,并且第一个字节就是保存的结构数量,也就是map_item的数量
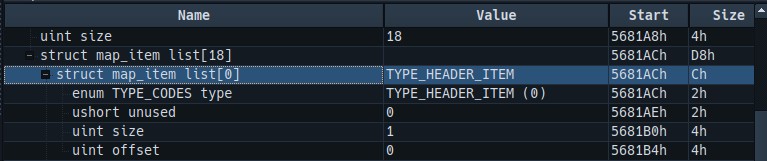
map_item结构如下图所示,单一结构长度位12个字节,其中前两个字节是描述对应的段类型,紧跟着的2个字节是对齐字节,无意义。接下来的4个字节是对应的段大小,最后的4个字节是对应的段偏移,以上就是关于mapoff对应的内容的解释
stringIdsSize && stringIdsOff字段
这两个字段是用来标记所有字符串的,stringIdsSize标记字符串的数量,stringIdsOff标记字符串偏移的首地址,知道这两个数据以后,我们就可以进行字符串的解析了.
struct DexStringId {
u4 stringDataOff; /* 字符串数据偏移 */
}我们先看一下stringIdsOff 这个值,截图如下
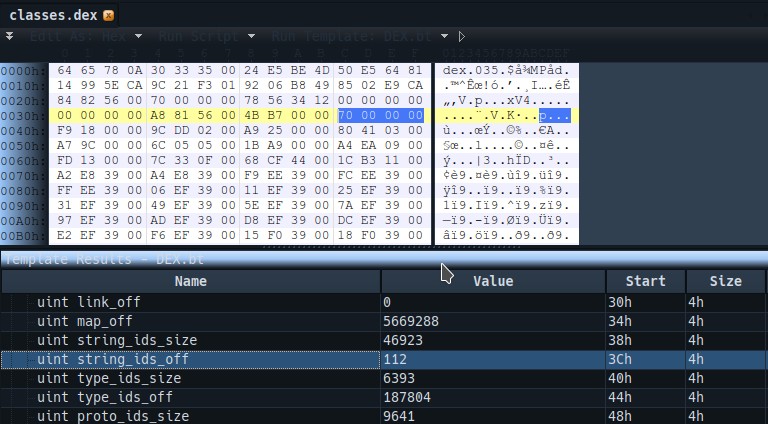
我们可以看到这个数值位 70 00 00 00,这个是不是很熟悉?我们去看一下,dex的header值是多少? 是70H,因为我们这个数值存放的问题,实际这个偏移值就是70H。
也就是说,我们的Dex头部的后面紧跟着就是字符串的相关数据了。我们接着说字符串数据的解析
我们把结构选择到010Editor的第二个结构体,也就是struct string_id_list dex_string_ids这里,选中这个结构体我们可以看到这个结构的全部内容。如下
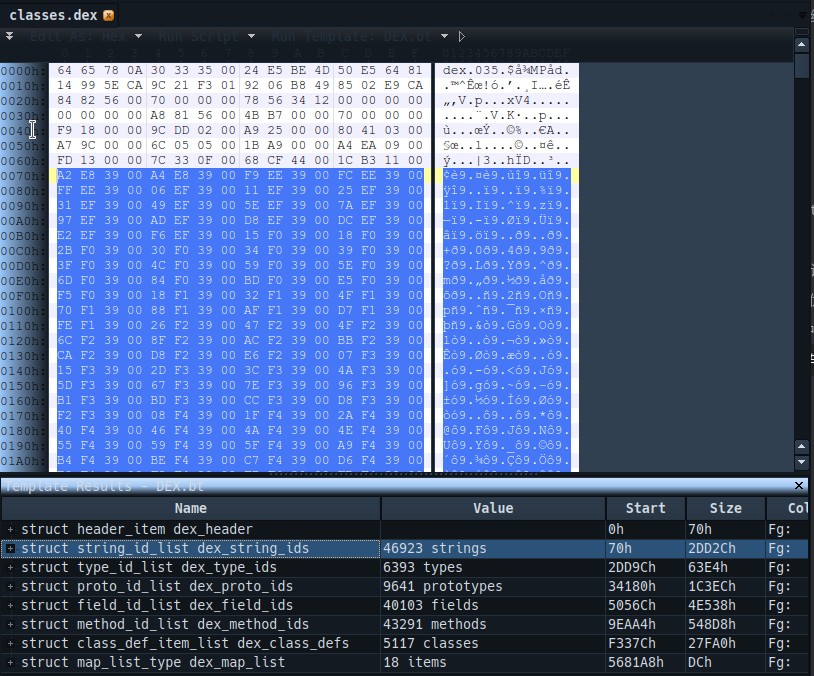
这里的展开的每一个item就是一个字符串的索引,这里强调一下是索引。不是真正的字符串。这个值对应的是真正的字符串的偏移地址,我们后面需要用到的字符串,会通过这个索引进行查表找到对应的字符串。
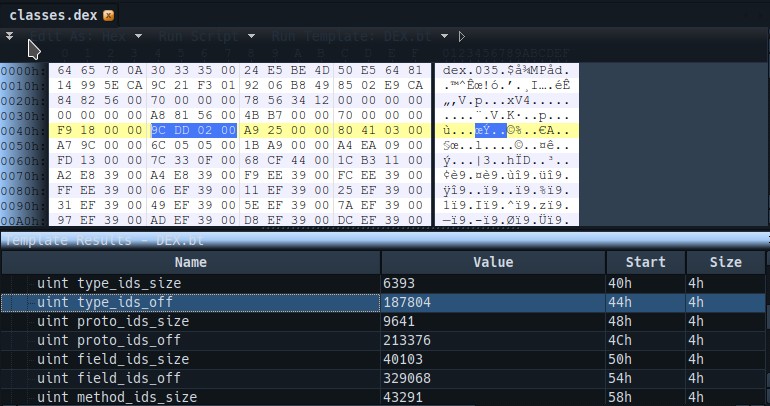
typeIdsSize & typeIdsOff
类型区的大小和对应的类型名字的偏移索引。
这个索引的起始地址就是typeIdsOff对应的值,这个值在我的dex文件上面是0x00 02 DD 9C,然后这个起始地址开始有6393个数据,我们现在跳转到对应的地址看一下。
struct DexTypeId {
u4 descriptorIdx; /* 指向 DexStringId列表的索引 */
};
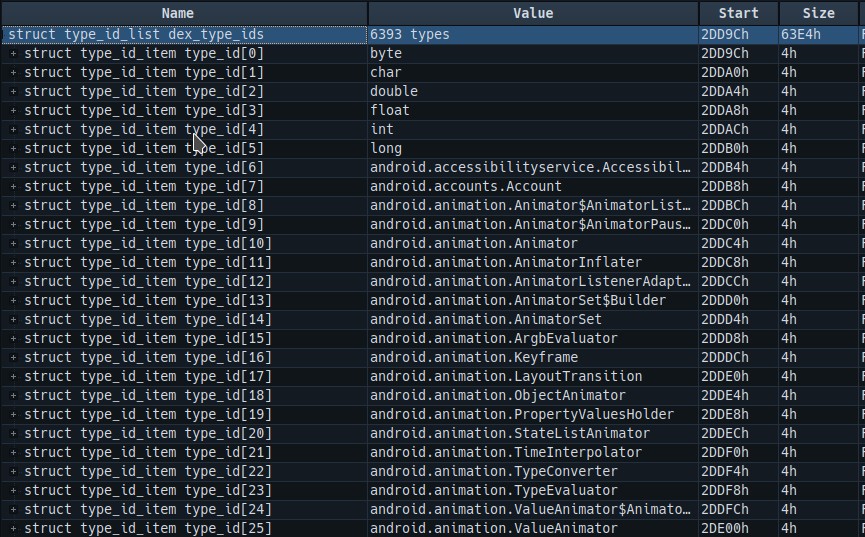
想要精准的跳到对应的地址,我们可以直接选择结构列表里面的struct type_id_list dex_type_ids,010Editor会自动帮我们定位到对应的位置,这个时候我们再来看一下这个结构的全部数据,已经被选中了.如果我们展开这个结构,下面是每一个item的索引和item的内部结构,我们可以数一下索引的值,我这里的是从0-6392,一共是6393个结构。所以这个刚好跟我们头部的数据是对应的。
接下来我们看一些type_id_item的值,大家可以在010Editor里面进行查看。里面能够看到很多的类型,例如byte,float,还有这个dex中的类对应的类型
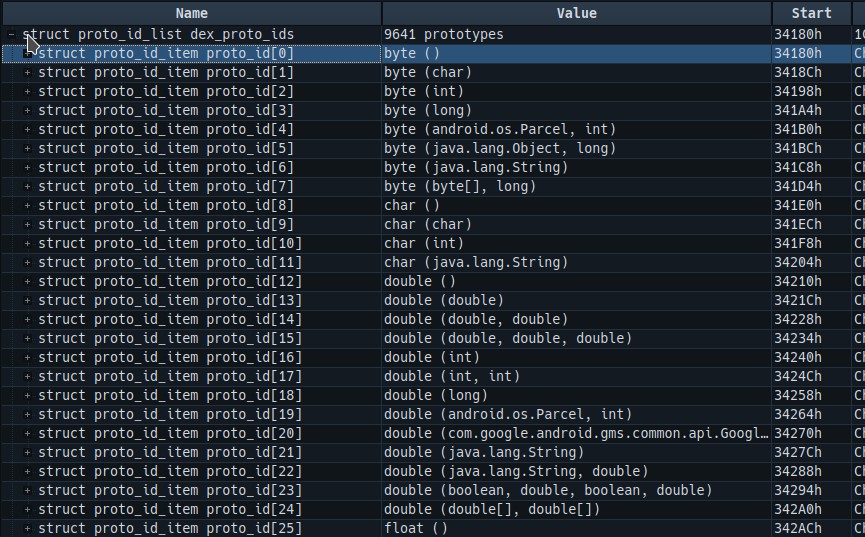
protoIdsSize & protoIdsOff
protoIdsOff指向了函数原型的偏移地址,主要的标记内容 方法声明=返回类型 + 参数列表,protoIds标记对应的数量.从对应的value里面,我们就能看到函数返回值,参数类型等函数原型的标记
zstruct DexProtoId {
u4 shortyIdx; /* 指向DexStringId列表的索引 */
u4 returnTypeIdx; /* 指向DexTypeId列表的索引 */
u4 parametersOff; /* 指向DexTypeList的偏移 */
}
struct DexTypeList {
u4 size; /* 接下来DexTypeItem的个数 */
DexTypeItem list[1]; /* DexTypeItem结构 */
};
struct DexTypeItem {
u2 typeIdx; /* 指向DexTypeId列表的索引 */
};
field_ids_size & field_ids_off
field_ids_off偏移地址指向的结构数据全部是索引值,指明了字段所在的类、字段的类型以及字段名
struct DexFieldId {
u2 classIdx; /* 类的类型,指向DexTypeId列表的索引 */
u2 typeIdx; /* 字段类型,指向DexTypeId列表的索引 */
u4 nameIdx; /* 字段名,指向DexStringId列表的索引 */
};具体请看下图,class_idx 这个field所属的类的索引值,type_idx是这个field对应的类型索引值,name_idx是这个字段的名称对应的索引值
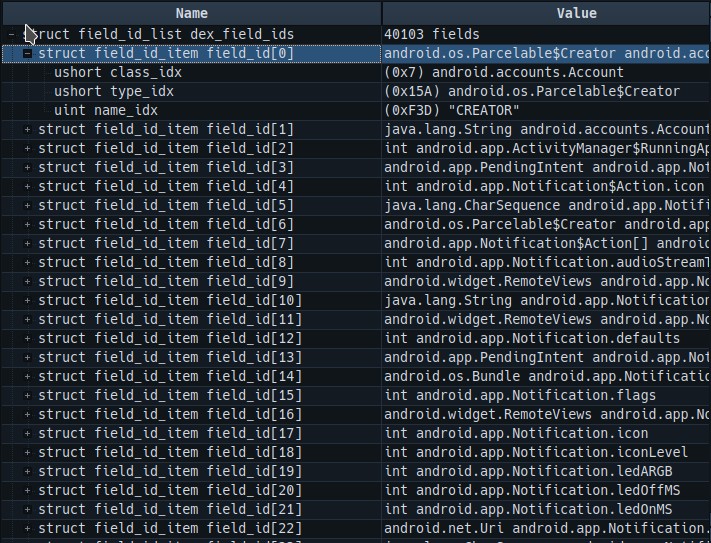
method_ids_size & method_ids_off
method_ids_off 指定了函数方法的偏移位置,具体的字段如下代码所示
struct DexMethodId {
u2 classIdx; /* 类的类型,指向DexTypeId列表的索引 */
u2 protoIdx; /* 声明类型,指向DexProtoId列表的索引 */
u4 nameIdx; /* 方法名,指向DexStringId列表的索引 */
};classIdx 指向这个方法所在的类对象的索引,通过索引可以获取到类对象的名称
protoIdx指向的是这个方法声明的原型字符串的索引
nameIdx获取这个方法名称的字符串索引
有了这三个索引对应的字符串,我们就可以获取到正确的类,方法名,参数和返回值,还是使用我们的010Editor,我们打开method_id_list dex_method_ids这个结构下面的item,我们就可以看到这些数据获取以后,我们能知道的一些东西,具体看下图
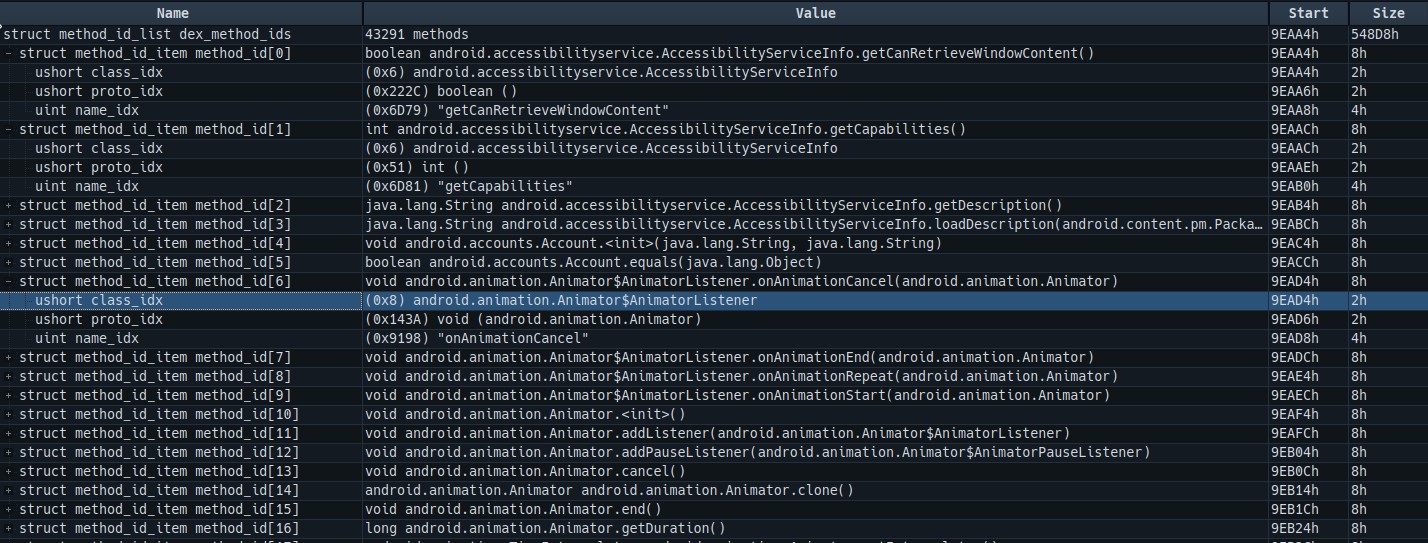
我们可以在结构体的最上面看到整个的方法原型,这个是由下面的三个字段对应的字符串值拼接成的,可以完整的看到方法的声明细节。
class_defs_size & class_defs_off
class_defs_off指向的是类定义的偏移地址,这里的类定义结构比较复杂,里面嵌套了很多层,我们先来看一下010Editor的结构
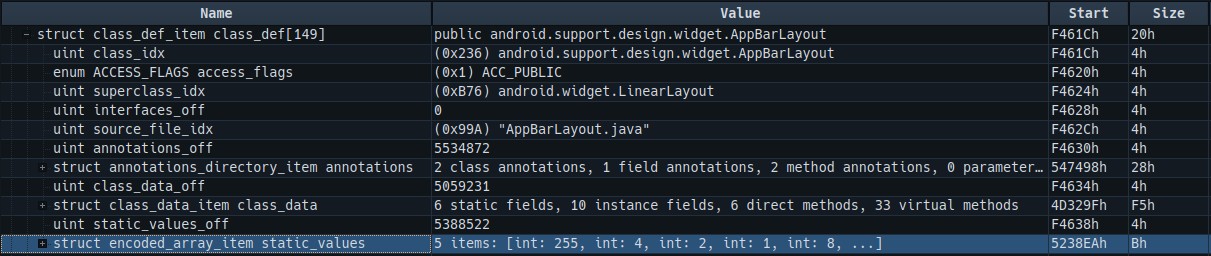
在这个结构里面,我们能看到一些基本的信息,比如class_idx索引等等,访问的标志等等,
class_def_item的结构如下
uint 32-bit unsigned int, little-endian
struct class_def_item
{
uint class_idx; //描述具体的 class 类型,值是 type_ids 的一个 index 。值必须是一个 class 类型,不能是数组类型或者基本类型。
uint access_flags; //描述 class 的访问类型,诸如 public , final , static 等。在 dex-format.html 里 “access_flags Definitions” 有具体的描述
uint superclass_idx; //描述 supperclass 的类型,值的形式跟 class_idx 一样
uint interface_off; //值为偏移地址,指向 class 的 interfaces,被指向的数据结构为 type_list 。class 若没有 interfaces 值为 0
uint source_file_idx; //表示源代码文件的信息,值是 string_ids 的一个 index。若此项信息缺失,此项值赋值为 NO_INDEX=0xffff ffff
uint annotations_off; //值是一个偏移地址,指向的内容是该 class 的注释,位置在 data 区,格式为 annotations_direcotry_item。若没有此项内容,值为 0
uint class_data_off; //值是一个偏移地址,指向的内容是该 class 的使用到的数据,位置在 data 区,格式为 class_data_item。若没有此项内容值为 0。该结构里有很多内容,详细描述该 class 的 field、method, method 里的执行代码等信息,后面会介绍 class_data_item
uint static_value_off; //值是一个偏移地址 ,指向 data 区里的一个列表 (list),格式为 encoded_array_item。若没有此项内容值为 0
}如果仔细对比你就会发现,010Editor会将annotations_off指向的数据放在他的后面,class_data_off,static_values_off也是一样的处理方式,其实这些数据都在dex结构的其他地方,但是010Editor为了让你查看方便,把他们都放在了一起,实际的class_def_item结构都是指向和偏移,真正的解析都在对应的地址位置而不在这个类定义的结构里面
class_def_item 中的 annotations_off指向的内容
annotations指向的是annotation 相关的数据描述,这个描述的结构具体如下
uint 32-bit unsigned int, little-endian
struct annotation_directory_item
{
uint class_annotations_off; //从文件开头到直接在该类上所做的注释的偏移量;如果该类没有任何直接注释,则该值为 0。该偏移量(如果为非零值)应该是到 data 区段中某个位置的偏移量。数据格式由下文的“annotation_set_item”指定。
uint fields_size;//此项所注释的字段数量
uint annotated_methods_size;//此项所注释的方法数量
uint annotated_parameters_size;//此项所注释的方法参数列表的数量
field_annotation field_annotations[fields_size];//(可选) 所关联字段的注释列表。该列表中的元素必须按 field_idx 以升序进行排序。
method_annotation method_annotations[annotated_methods_size];//(可选) 所关联方法的注释列表。该列表中的元素必须按 method_idx 以升序进行排序。
parameter_annotation parameter_annotations[annotated_parameters_size];//(可选)所关联方法参数的注释列表。该列表中的元素必须按 method_idx 以升序进行排序。
}
struct field_annotation
{
uint field_idx;//字段(带注释)标识的 field_ids 列表中的索引
uint annotations_off; //字段(带注释)标识的 field_ids 列表中的索引
}
struct method_annotation
{
uint method_idx;//方法(带注释)标识的 method_ids 列表中的索引
uint annotations_off; //从文件开头到该方法注释列表的偏移量。偏移量应该是到 data 区段中某个位置的偏移量。数据格式由下文的“annotation_set_item”指定。
}
struct parameter_annotation
{
uint method_idx;//方法(其参数带注释)标识的 method_ids 列表中的索引
uint annotations_off; //从文件开头到该方法参数的注释列表的偏移量。偏移量应该是到 data 区段中某个位置的偏移量。数据格式由下文的“annotation_set_ref_list”指定。
}
struct annotation_set_ref_list
{
unit size;//列表的大小(以条目数表示)
annotation_set_ref_item[size] list;//列表的元素
}
struct annotation_set_ref_item
{
unit annotations_off; //从文件开头到所引用注释集的偏移量;如果此元素没有任何注释,则该值为 0。该偏移量(如果为非零值)应该是到 data 区段中某个位置的偏移量。数据格式由下文的“annotation_set_item”指定。
}
struct annotation_set_item
{
unit size; //该集合的大小(以条目数表示)
annotation_off_item[size] entries; //该集合的元素。这些元素必须按 type_idx 以升序进行排序。
}
struct annotation_off_item
{
unit annotation_off; //从文件开头到注释的偏移量。该偏移量应该是到 data 区段中某个位置的偏移量,且该位置的数据格式由下文的“annotation_item”指定。
}
struct annotation_item
{
ubyte visibility; //此注释的预期可见性(见下文)
encoded_annotation annotation; //已编码的注释内容,采用上文的“encoded_value 编码”下的“encoded_annotation 格式”所述的格式。
}
//可见值
// VISIBILITY_BUILD 0x00 预计仅在构建时(例如,在编译其他代码期间)可见
//VISIBILITY_RUNTIME 0x01 预计在运行时可见
//VISIBILITY_SYSTEM 0x02 预计在运行时可见,但仅对基本系统(而不是常规用户代码)可见
struct encoded_array_item
{
encoded_array value; //用于表示编码数组值的字节,采用上文的“encoded_value 编码”下的“encoded_array 格式”指定的格式。
}
struct hiddenapi_class_data_item
{
unit size; //该区段的总大小
unit[] offsets; //由 class_idx 编入索引的偏移量数组。索引 class_idx 中的零数组意味着此 class_idx 没有任何数据,或者所有隐藏 API 标记均为零。否则,数组条目为非零值,并且包含从该区段开头到此 class_idx 的隐藏 API 标记数组的偏移量。
bleb128[] flags; //每个类的隐藏 API 标记的级联数组。可能的标记值如下表所述。标记按照字段的相同编码顺序进行编码,且方法在类数据中编码。
}
限制标记类型:
名称 值 说明
whitelist 0 此列表中的接口已在 Android 框架软件包索引中正式记录,它们是受支持的接口,您可以自由使用。
greylist 1 包含可以使用的非 SDK 接口的列表(无论应用的目标 API 级别是什么)。
blacklist 2 包含不能使用的非 SDK 接口的列表(无论应用的目标 API 级别是什么)。访问其中任何一个接口都会导致运行时错误。
greylist‑max‑o 3 包含可用于 Android 8.x 及下文的非 SDK 接口列表(除非这些接口受到限制)。
greylist‑max‑p 4 包含可用于 Android 9.x 的非 SDK 接口列表(除非这些接口受到限制)。
greylist‑max‑q 5 包含可用于 Android 10.x 的非 SDK 接口列表(除非这些接口受到限制)。
如果需要可以参考google的官方文档(需要翻墙)
https://source.android.com/devices/tech/dalvik/dex-format.html
class_def_item中的class_data_off
指向 data 区里的 class_data_item 结构,class_data_item 里存放着本 class 使用到的各种数据,下面是 class_data_item 的结构
uleb128 unsigned little-endian base 128
struct class_data_item
{
uleb128 static_fields_size; //静态成员变量的个数
uleb128 instance_fields_size; //实例成员变量个数
uleb128 direct_methods_size; //直接函数个数
uleb128 virtual_methods_size; // 虚函数个数
encoded_field static_fields[static_fields_size];
encoded_field instance_fields[instance_fields_size];
encoded_method direct_methods[direct_methods_size];
encoded_method virtual_methods[virtual_methods_size];
}
struct encoded_field
{
uleb128 filed_idx_diff;
uleb128 access_flags;
}
struct encoded_method
{
uleb128 method_idx_diff; //前缀 methd_idx 表示它的值是 method_ids 的一个 index ,后缀 _diff 表示它是于另 外一个 method_idx 的一个差值 ,就是相对于 encodeed_method [] 数组里上一个元素的 method_idx 的差值 。 其实 encoded_filed - > field_idx_diff 表示的也是相同的意思 ,只是编译出来的 Hello.dex 文件里没有使用到 class filed 所以没有仔细讲 ,详细的参考 https://source.android.com/devices/tech/dalvik/dex-format 官网文档。
uleb128 access_flags; //访问权限,比如 public、private、static、final 等
uleb128 code_off;//一个指向 data 区的偏移地址,目标是本 method 的代码实现。被指向的结构是code_item,有近 10 项元素
}
struct code_item
{
ushort registers_size; //本段代码使用到的寄存器数目
ushort ins_size; //method 传入参数的数目
ushort outs_size; //本段代码调用其它 method 时需要的参数个数
ushort tries_size;//try_item 结构的个数
uint debug_info_off;//偏移地址,指向本段代码的 debug 信息存放位置,是一个 debug_info_item 结构
uint insns_size;
ushort insns [insns_size];
ushort paddding; // optional
try_item tries [tyies_size]; // optional
encoded_catch_handler_list handlers; // optional
}
struct debug_info_off
{
uleb128 line_start;//状态机的 line 寄存器的初始值。不表示实际的位置条目
uleb128 parameters_size;//已编码的参数名称的数量。每个方法参数都应该有一个名称,但不包括实例方法的 this(如果有)
uleb128p1[parameters_size] paramer_names;//方法参数名称的字符串索引。NO_INDEX 的编码值表示该关联参数没有可用的名称。该类型描述符和签名隐含在方法描述符和签名中
}class_def_item中的static_value_off
uleb128 unsigned LEB128, valriable length
struct encoded_array_item
{
encoded_array value; //表示encoded_value 个数
}
struct encoded_array
{
uleb128 size;
encoded_value values[size];
}map_list
我们在前面已经提到过这个map_list,他里面的内容是保存header中对应的描述,里面描述的更加全面,具体的结构如下
map_list 里先用一个 uint 描述后面有 size 个 map_item,后续就是对应的 size 个 map_item 描述。 map_item 结构有 4 个元素: type 表示该 map_item 的类型,Dalvik Executable Format 里 Type Code 的定义; size 表示再细分此 item,该类型的个数;offset 是第一个元素的针对文件初始位置的偏移量; unuse 是用对齐字节的,无实际用处。
ushort 16-bit unsigned int, little-endian
uint 32-bit unsigned int, little-endian
struct map_list
{
uint size;
map_item list [size];
}
struct map_item
{
ushort type;
ushort unuse;
uint size;
uint offset;
} leb128编码
Dalvik使用readUnsignedLeb128函数来尝试读取一个leb128编码的数值(代码位于dalvik\libdex\Leb128.h中),那么什么是uleb128呢?
LEB128即”Little-Endian Base 128”,基于128的小端序编码格式,是对任意有符号或者无符号整型数的可变长度的编码。用LEB128编码的正数,会根据数字的大小改变所占字节数。在android的.dex文件中,他只用来编码32bits的整型数。

例子
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130/*
* Reads an unsigned LEB128 value, updating the given pointer to point
* just past the end of the read value. This function tolerates
* non-zero high-order bits in the fifth encoded byte.
*/
DEX_INLINE int readSignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result <= 0x7f) {
result = (result << 25) >> 25;
} else {
int cur = *(ptr++);
result = (result & 0x7f) | ((cur & 0x7f) << 7);
if (cur <= 0x7f) {
result = (result << 18) >> 18;
} else {
cur = *(ptr++);
result |= (cur & 0x7f) << 14;
if (cur <= 0x7f) {
result = (result << 11) >> 11;
} else {
cur = *(ptr++);
result |= (cur & 0x7f) << 21;
if (cur <= 0x7f) {
result = (result << 4) >> 4;
} else {
cur = *(ptr++);
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}对应的Kotlin代码,我自己写的功能,请大家参考
private fun decodeUleb128(data: ByteArray): Long {
var result: Long = 0L
parserByte@
for (index in data.indices) {
val cur = data[index].toUInt()
when (index) {
0 -> {
result = cur.toLong()
if (cur <= 127u) {
//就一个byte,直接赋值,跳出循环
break@parserByte
}
//最高位为1,继续保存值到result里面,继续下一次循环
}
1 -> {
//拼接数据,这里对result的值进行and操作,去掉高位数据
val lowVal = (result and 0x7f).toInt()
val hiVal = (cur and 127u).toInt() shl 7
result = (lowVal or hiVal).toLong()
if (cur <= 127u) {
//如果最高位不是0,没有数据了,直接返回
break@parserByte
}
//什么都不做,等着下一次循环,继续操作
}
2 -> {
val hiVal = ((cur and 127u).toInt() shl 14)
result = result or hiVal.toLong()
if (cur <= 127u) {
break@parserByte
}
}
3 -> {
val hiVal = (cur and 127u).toInt() shl 21
result = result or hiVal.toLong()
if (cur <= 127u) {
break@parserByte
}
}
4 -> {
val hiVal = cur.toInt() shl 28
result = result or hiVal.toLong()
if (cur <= 127u) {
break@parserByte
}
}
}
}
return result
}


